DockerによるPyTorch GPU環境の構築
前の記事「NVIDIA Drivers for CUDA on WSL(WLS2)でTensorFlow-GPUが動くまでの構築手順」では、WSL2のUbuntu20.04にDockerコンテナを利用してGPU版のTensorFlowを比較的簡単に利用できる方法を紹介しました。以降は、この環境でTensorFlowを利用しており、現在まで大きな問題は起っていません(そのままの環境を使い続けただけとも言えます)。
しかし、今年に入って自前のPCでPyTorchを利用する機会ができたことから、以前の記事の環境を前提にして、効率が良さそうな環境構築の方法を検討することにしました。PyTorch自体は、現在もABCIというクラウドのコンピューティング環境で利用していますが、契約の切替え期間中のため利用ができなかったためです。また、ローカルにはGPUが利用できるPyTorch環境はありませんでした。
そこで、目指すのは使い慣れたABCIのPyTorch環境と同じく、数行のコマンドで環境が作れる方法となります。
結論として、以前のGPUが動作するWSL2上のUbuntu20.04では、NVIDIA社のPyTorchイメージを利用する方法が最も少ない作業で環境構築を行えるといえます。
TOC
1.既存のTensorFlow-GPU環境にPyTorchを追加する
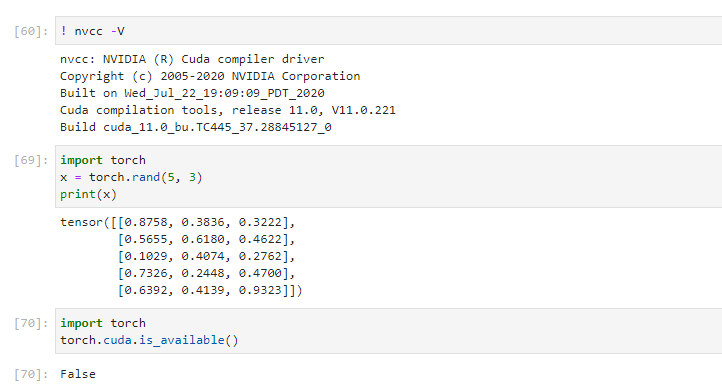
タイトルの雰囲気からいっても、無理筋な匂いが漂ってきます。実際に、PyTorchの公式サイトで得たコマンドで必要なライブラリを実行してもGPUは認識してくれませんでした。

インストール後、同ページの検証コードを実行したところ、やはりGPUが認識しませんでした。
考察
ここでGPUを認識しない理由としては、以下のことが考えられる。
-
- ドライバなどのバージョンの不整合による問題
- 不足のライブラリがある(e.g. CuDNNなど)
- その他、どこかの手順が不足している
いずれの問題にせよ、使い捨てコンテナ内に複数の操作を加えることは避けたいので、これ以上の原因解明と解決法の探索は行わない。
2.PyTorchのビルド済みイメージを使う(1)
次に、Dockerのpytorch/pytorchイメージを試しました。しかし、これもGPUは認識しませんでした。原因の探索はせず、あきらめて3の方法へ進みます。今回は環境構築に時間を消費したくないためです。
3.PyTorchのビルド済みイメージを使う(2)
さて、真打はNvidia社のPyTorch NGCコンテナというものです。環境の前提条件は、以下の通りです。
Prerequisites
Using the PyTorch NGC Container requires the host system to have the following installed:
For supported versions, see the Framework Containers Support Matrix and the NVIDIA Container Toolkit Documentation.
No other installation, compilation, or dependency management is required. It is not necessary to install the NVIDIA CUDA Toolkit.
以前の環境であれば、要件は満たしていそうです。コンテナのバージョンは、ドライバーとの対応から、20.12を選択しました(以下のコマンドのxx.xxを置き換えて実行します)。
docker run --gpus all -it --shm-size=YOUR-MEMORY-SIZE -v local_dir:container_dir nvcr.io/nvidia/pytorch:xx.xx-py3
コンテナを起動したら、コンテナ内のシェルからPyTorchの検証コードを実行してみます。
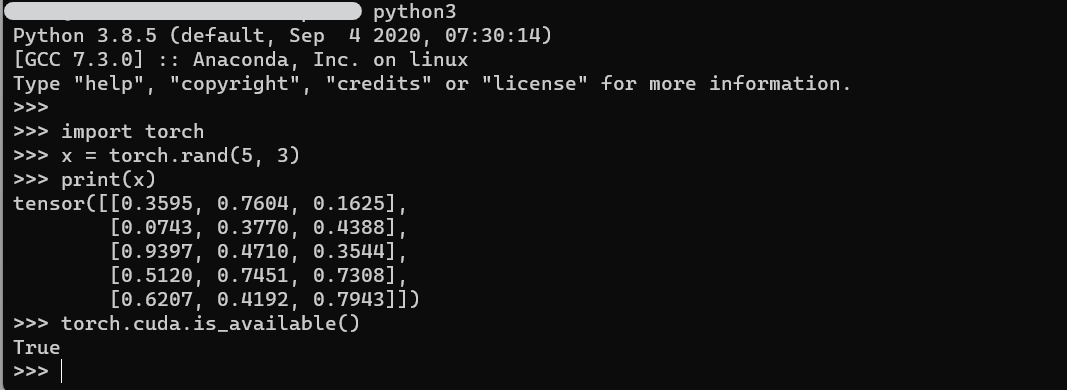
無事、True が返ってきました。
Enjoy!!